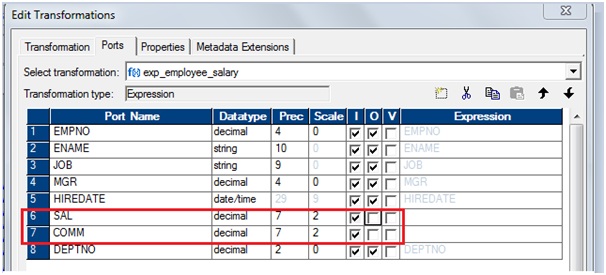
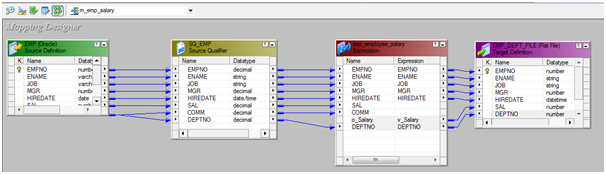
The
PowerCenter Integration Service moves data from sources to targets based on
PowerCenter workflow, session and mapping related metadata stored in a PowerCenter repository.
When a workflow starts, the PowerCenter Integration Service retrieves mapping, session and workflow related metadata from the repository.
It extracts data from the
mapping sources and stores the data in memory while it applies the
transformation rules configured in the mapping. The PowerCenter Integration
Service loads the transformed data into one or more targets.
To move data
from sources to targets, the PowerCenter Integration Service uses components are PowerCenter Integration Service Process, Load Balancer and Data Transformation Manager process (DTM):
·
PowerCenter
Integration Service process: The PowerCenter Integration Service starts one or
more PowerCenter Integration Service processes to run and monitor workflows.
When a workflow run, the PowerCenter Integration Service process starts and
locks the workflow, runs the workflow tasks, and starts the process to run
sessions.
·
Load
Balancer: The PowerCenter Integration Service uses the Load Balancer to
dispatch tasks. The Load Balancer dispatches tasks to achieve optimal
performance. It may dispatch tasks to a single node or across the nodes in a
grid.
·
Data
Transformation Manager (DTM) process: The PowerCenter Integration Service
starts a DTM process to run each Session and Command task within a workflow.
The DTM process performs session validations, creates threads to initialize the
session, read, write, and transform data, and handles pre- and post- session
operations.
PowerCenter Integration Service Connectivity:
The
PowerCenter Integration Service is a repository client. It connects to the
PowerCenter Repository Service to retrieve workflow and mapping metadata from
the repository database. When the PowerCenter Integration Service process
requests a repository connection, the request is routed through the master
gateway, which sends back PowerCenter Repository Service information to the
PowerCenter Integration Service process. The PowerCenter Integration Service
process connects to the PowerCenter Repository Service. The PowerCenter
Repository Service connects to the repository and performs repository metadata
transactions for the client application.
The
PowerCenter Workflow Manager communicates with the PowerCenter Integration
Service process over a TCP/IP connection. The PowerCenter Workflow Manager
communicates with the PowerCenter Integration Service process each time you
schedule or edit a workflow, display workflow details, and request workflow and
session logs. Use the connection information defined for the domain to access
the PowerCenter Integration Service from the PowerCenter Workflow Manager.
The
PowerCenter Integration Service process connects to the source or target
database using ODBC or native drivers. The PowerCenter Integration Service
process maintains a database connection pool for stored procedures or lookup
databases in a workflow. The PowerCenter Integration Service process allows an
unlimited number of connections to lookup or stored procedure databases. If a database
user does not have permission for the number of connections a session requires,
the session fails. You can optionally set a parameter to limit the database
connections. For a session, the PowerCenter Integration Service process holds
the connection as long as it needs to read data from source tables or write
data to target tables.
PowerCenter Integration Service:
The PowerCenter Integration Service is an application
service that runs sessions and workflows.
Integration Service Process:
The
PowerCenter Integration Service starts a PowerCenter Integration Service
process to run and monitor workflows. The PowerCenter Integration Service
process is also known as the pmserver process. The PowerCenter Integration
Service process accepts requests from the PowerCenter Client and from pmcmd.
It
performs the following tasks:
·
Manage workflow
scheduling.
·
Lock and read the
workflow.
·
Read the parameter
file.
·
Create the workflow
log.
·
Run workflow tasks and
evaluates the conditional links connecting tasks.
·
Start the DTM process
or processes to run the session.
·
Write historical run
information to the repository.
·
Send post-session
email in the event of a DTM failure.
Load Balancer:
The Load Balancer is the object of the PowerCenter
Integration Service and that dispatches tasks to achieve optimal performance
and scalability. When you run a workflow, the Load Balancer dispatches the
Session, Command, and predefined Event-Wait tasks within the workflow. The Load
Balancer matches task requirements with resource availability to identify the
best node to run a task. It dispatches the task to a PowerCenter Integration Service
process running on the node. It may dispatch tasks to a single node or across
nodes.
The
Load Balancer dispatches tasks in the order it receives them. When the Load
Balancer needs to dispatch more Session and Command tasks than the PowerCenter
Integration Service can run, it places the tasks it cannot run in a queue. When
nodes become available, the Load Balancer dispatches tasks from the queue in
the order determined by the workflow service level.
The Load Balancer functionality:
·
Dispatch
process: The Load Balancer performs several steps to dispatch tasks.
·
Resources:
The Load Balancer can use PowerCenter resources to determine if it can dispatch
a task to a node.
·
Resource
provision thresholds: The Load Balancer uses resource provision thresholds to
determine whether it can start additional tasks on a node.
·
Dispatch
mode: The dispatch mode determines how the Load Balancer selects nodes for
dispatch.
·
Service
levels: When multiple tasks are waiting in the dispatch queue, the Load
Balancer uses service levels to determine the order in which to dispatch tasks
from the queue.
Data Transformation Manager (DTM) Process
The PowerCenter Integration Service process starts the
DTM process to run a session. The DTM process is also known as the pmdtm
process. The DTM is the process associated with the session task.
Read the Session Information: The PowerCenter Integration Service process provides the
DTM with session instance information when it starts the DTM. The DTM retrieves
the mapping and session metadata from the repository and validates it.
Perform Pushdown Optimization: If the session is configured for pushdown optimization,
the DTM runs an SQL statement to push transformation logic to the source or
target database.
Create Dynamic Partitions: The DTM adds partitions to the session if you configure
the session for dynamic partitioning. The DTM scales the number of session
partitions based on factors such as source database partitions or the number of
nodes in a grid.
Form Partition Groups: If you run a session on a grid, the DTM forms partition
groups. A partition group is a group of reader, writer, and transformation threads
that runs in a single DTM process. The DTM process forms partition groups and
distributes them to worker DTM processes running on nodes in the grid.
Expand Variables and Parameters: If the workflow uses a parameter file, the PowerCenter
Integration Service process sends the parameter file to the DTM when it starts
the DTM. The DTM creates and expands session-level, service-level, and
mapping-level variables and parameters.
Create the Session Log: The DTM creates logs for the session. The session log
contains a complete history of the session run, including initialization,
transformation, status, and error messages. You can use information in the
session log in conjunction with the PowerCenter Integration Service log and the
workflow log to troubleshoot system or session problems.
Validate Code Pages: The PowerCenter Integration Service processes data
internally using the UCS-2 character set. When you disable data code page
validation, the PowerCenter Integration Service verifies that the source query,
target query, lookup database query, and stored procedure call text convert
from the source, target, lookup, or stored procedure data code page to the
UCS-2 character set without loss of data in conversion. If the PowerCenter
Integration Service encounters an error when converting data, it writes an
error message to the session log.
Verify Connection Object Permissions: After validating the session code pages, the DTM verifies
permissions for connection objects used in the session. The DTM verifies that
the user who started or scheduled the workflow has execute permissions for
connection objects associated with the session.
Start Worker DTM Processes: The DTM sends a request to the PowerCenter Integration
Service process to start worker DTM processes on other nodes when the session
is configured to run on a grid.
Run Pre-Session Operations: After verifying connection object permissions, the DTM
runs pre-session shell commands. The DTM then runs pre-session stored
procedures and SQL commands.
Run the Processing Threads: After initializing the session, the DTM uses reader,
transformation, and writer threads to extract, transform, and load data. The
number of threads the DTM uses to run the session depends on the number of
partitions configured for the session.
Run Post-Session Operations: After the DTM runs the processing threads, it runs
post-session SQL commands and stored procedures. The DTM then runs post-session
shell commands.
Send Post-Session Email: When the session finishes, the DTM composes and sends
email that reports session completion or failure. If the DTM terminates
abnormally, the PowerCenter Integration Service process sends post-session
email.
Processing Threads
The DTM allocates process memory for the session and
divides it into buffers. This is also known as buffer memory. The DTM uses
multiple threads to process data in a session. The main DTM thread is called
the master thread.
The different types of master threads creates for a session:
·
Mapping
threads
The master thread creates one mapping thread for each
session. The mapping thread fetches session and mapping information, compiles
the mapping, and cleans up after session execution.
·
Pre-
and post-session threads
The master thread creates one pre-session and one
post-session thread to perform pre- and post-session operations.
·
Reader
threads
The master thread creates reader threads to extract
source data. The number of reader threads depends on the partitioning information
for each pipeline. The number of reader threads equals the number of
partitions. Relational sources use relational reader threads, and file sources
use file reader threads.
The PowerCenter Integration Service creates an SQL
statement for each reader thread to extract data from a relational source. For
file sources, the PowerCenter Integration Service can create multiple threads
to read a single source.
·
Transformation
threads
The master thread creates one or more transformation
threads for each partition. Transformation threads process data according to
the transformation logic in the mapping.
The master thread creates transformation threads to
transform data received in buffers by the reader thread, move the data from
transformation to transformation, and create memory caches when necessary. The
number of transformation threads depends on the partitioning information for
each pipeline.
Transformation threads store transformed data in a buffer
drawn from the memory pool for subsequent access by the writer thread.
If the pipeline contains a Rank, Joiner, Aggregator,
Sorter, or a cached Lookup transformation, the transformation thread uses cache
memory until it reaches the configured cache size limits. If the transformation
thread requires more space, it pages to local cache files to hold additional
data.
When the PowerCenter Integration Service runs in ASCII
mode, the transformation threads pass character data in single bytes. When the
PowerCenter Integration Service runs in Unicode mode, the transformation
threads use double bytes to move character data.
·
Writer
threads
The master thread creates writer threads to load target
data. The number of writer threads depends on the partitioning information for
each pipeline. If the pipeline contains one partition, the master thread
creates one writer thread. If it contains multiple partitions, the master
thread creates multiple writer threads.
Each writer thread creates connections to the target
databases to load data. If the target is a file, each writer thread creates a
separate file. You can configure the session to merge these files.
If the target is relational, the writer thread takes data
from buffers and commits it to session targets. When loading targets, the
writer commits data based on the commit interval in the session properties. You
can configure a session to commit data based on the number of source rows read,
the number of rows written to the target, or the number of rows that pass
through a transformation that generates transactions, such as a Transaction
Control transformation.
Grids
When you run a PowerCenter Integration Service on a grid,
a master service process runs on one node and worker service processes run on
the remaining nodes in the grid. The master service process runs the workflow
and workflow tasks, and it distributes the Session, Command, and predefined
Event-Wait tasks to itself and other nodes. A DTM process runs on each node
where a session runs. If a session run on a grid, a worker service process
can run multiple DTM processes on different nodes to distribute session threads.
Code Pages and Data Movement Modes
The PowerCenter Integration Service can move data in
either ASCII or Unicode data movement mode. These modes determine how the
PowerCenter Integration Service handles character data. You choose the data
movement mode in the PowerCenter Integration Service configuration settings. If
you want to move multibyte data, choose Unicode data movement mode. To ensure
that characters are not lost during conversion from one code page to another,
you must also choose the appropriate code pages for your connections.
ASCII
Data Movement Mode
In ASCII data movement mode when all sources and targets
are 7-bit ASCII or EBCDIC character sets. In ASCII mode, the PowerCenter
Integration Service recognizes 7-bit ASCII and EBCDIC characters and stores
each character in a single byte.
Unicode
Data Movement Mode
Use Unicode data movement mode when sources or targets
use 8-bit or multibyte character sets and contain character data. In Unicode
mode, the PowerCenter Integration Service recognizes multibyte character sets
as defined by supported code pages.