



Lookup
Transformation is Passive/Active and it can be Connected/Unconnected.
A
Lookup transformation can used to look up data in a flat file, relational
table, view, or synonym. You can import a lookup definition from any flat file
or relational database to which both the PowerCenter Client and Integration
Service can connect. You can also create a lookup definition from a source
qualifier. You can use multiple Lookup transformations in a mapping.
The
Integration Service queries the lookup source based on the lookup ports in the
transformation and a lookup condition. The Lookup transformation returns the
result of the lookup to the target or another transformation. You can configure
the Lookup transformation to return a single row or multiple rows.
Perform
the following tasks with a Lookup transformation:
- Get a related value. Retrieve a value from the lookup table based on a
value in the source. For example, the source EMP table having DEPTNO but
we don't have DNAME. We can get it by doing lookup on DEPT table based on
condition DEPT.DEPTNO=EMP.DEPTNO.
- Get multiple values. Retrieve multiple rows from a lookup table. For
example, the DEPT table having DEPTNO but we don't have EMPNO's in that
department, we can return all employees in a department.
- Perform a calculation. Retrieve a Employees who's SAL > 2000 from a
lookup table. We will be using Lookup SQL Override query.
- Update slowly changing
dimension tables. This
is used to determine whether rows exist in a target.
Configure the Lookup transformation
to perform the following types of lookups:
- Relational or flat file lookup.
Perform a lookup on a flat file or a relational table. When you create a
Lookup transformation using a relational table as the lookup source, you
can connect to the lookup source using ODBC and import the table
definition as the structure for the Lookup transformation. When you create
a Lookup transformation using a flat file as a lookup source, the Designer
invokes the Flat File Wizard.
- Pipeline lookup. Perform a
lookup on application sources such as a JMS, MSMQ, or SAP. Drag the source
into the mapping and associate the Lookup transformation with the source
qualifier. Configure partitions to improve performance when the
Integration Service retrieves source data for the lookup cache.
- Connected or unconnected
lookup. A connected Lookup transformation receives source data, performs a
lookup, and returns data to the pipeline. An unconnected Lookup
transformation is not connected to a source or target. A transformation in
the pipeline calls the Lookup transformation with a :LKP expression. The
unconnected Lookup transformation returns one column to the calling
transformation.
- Cached or uncached lookup.
Cache the lookup source to improve performance. If you cache the lookup
source, you can use a dynamic or static cache. By default, the lookup
cache remains static and does not change during the session. With a
dynamic cache, the Integration Service inserts or updates rows in the
cache. When you cache the target table as the lookup source, you can look
up values in the cache to determine if the values exist in the target. The
Lookup transformation marks rows to insert or update the target.
Lookup Source Types
When
we create a Lookup transformation, we can choose a relational table, flat file,
or a source qualifier as the lookup source.
Relational Lookups
When
we create a Lookup transformation using a relational table as a lookup source,
we can connect to the lookup source using ODBC and import the table definition
as the structure for the Lookup transformation.
Use
the following options with relational lookups:
- Override the default SQL
statement to add a WHERE clause or to query multiple tables.
- Sort null data high or low,
based on database support.
- Perform case-sensitive
comparisons based on the database support.
Flat File Lookups
When
we create a Lookup transformation using a flat file as a lookup source, select
a flat file definition in the repository or import the source when you create
the transformation. When you import a flat file lookup source, the Designer
invokes the Flat File Wizard.
Use
the following options with flat file lookups:
- Use indirect files as lookup
sources by configuring a file list as the lookup file name.
- Use sorted input for the
lookup.
- Sort null data high or low.
- Use case-sensitive string
comparison with flat file lookups.
Using Sorted Input
When
we configure a flat file Lookup transformation for sorted input, the condition
columns must be grouped. If the condition columns are not grouped, the Lookup
transformation returns incorrect results. For optimal caching performance, sort
the condition columns.
For
example, a Lookup transformation has the following condition:
OrderID
= OrderID1 CustID = CustID1
In
the flat file lookup source, the keys are grouped, but not sorted. The
Integration Service can cache the data, but performance may not be optimal.
If
we choose sorted input for indirect files, the range of data must not overlap
in the files.
Connected and Unconnected Lookups
We
can configure a connected Lookup transformation to receive input directly from
the mapping pipeline, or you can configure an unconnected Lookup transformation
to receive input from the result of an expression in another transformation.
Connected
Lookup
|
Unconnected
Lookup
|
Receives
input values directly from the pipeline.
|
Receives
input values from the result of a :LKP expression in another transformation.
|
Use
a dynamic or static cache.
|
Use
a static cache.
|
Cache
includes the lookup source columns in the lookup condition and the lookup
source columns that are output ports.
|
Cache
includes all lookup/output ports in the lookup condition and the
lookup/return port.
|
Can
return multiple columns from the same row or insert into the dynamic lookup
cache.
|
Designate
one return port (R). Returns one column from each row.
|
If
there is no match for the lookup condition, the Integration Service returns
the default value for all output ports. If you configure dynamic caching, the
Integration Service inserts rows into the cache or leaves it unchanged.
|
If
there is no match for the lookup condition, the Integration Service returns
NULL.
|
If
there is a match for the lookup condition, the Integration Service returns
the result of the lookup condition for all lookup/output ports. If you
configure dynamic caching, the Integration Service either updates the row the
in the cache or leaves the row unchanged.
|
If
there is a match for the lookup condition, the Integration Service returns the
result of the lookup condition into the return port.
|
Pass
multiple output values to another transformation. Link lookup/output ports to
another transformation.
|
Pass
one output value to another transformation. The lookup/output/return port
passes the value to the transformation calling :LKP expression.
|
Supports
user-defined default values.
|
Does
not support user-defined default values.
|
Connected Lookup Transformation
The
following steps describe how the Integration Service processes a connected
Lookup transformation:
- A connected Lookup
transformation receives input values directly from another transformation
in the pipeline.
- For each input row, the
Integration Service queries the lookup source or cache based on the lookup
ports and the condition in the transformation.
- If the transformation is
uncached or uses a static cache, the Integration Service returns values
from the lookup query.
- If the transformation uses a
dynamic cache, the Integration Service inserts the row into the cache when
it does not find the row in the cache. When the Integration Service finds
the row in the cache, it updates the row in the cache or leaves it
unchanged. It flags the row as insert, update, or no change.
- The Integration Service passes
return values from the query to the next transformation.
- If the transformation uses a
dynamic cache, you can pass rows to a Filter or Router transformation to
filter new rows to the target.
Note: This chapter discusses connected Lookup
transformations unless otherwise specified.
Unconnected Lookup Transformation
An
unconnected Lookup transformation receives input values from the result of a
:LKP expression in another transformation. You can call the Lookup
transformation more than once in a mapping.
A
common use for unconnected Lookup transformations is to update slowly changing
dimension tables.
The
following steps describe the way the Integration Service processes an
unconnected Lookup transformation:
- An unconnected Lookup
transformation receives input values from the result of a :LKP expression
in another transformation, such as an Update Strategy transformation.
- The Integration Service queries
the lookup source or cache based on the lookup ports and condition in the
transformation.
- The Integration Service returns
one value into the return port of the Lookup transformation.
- The Lookup transformation
passes the return value into the :LKP expression.
Lookup Components
Define
the following components when you configure a Lookup transformation in a
mapping:
- Lookup source
- Ports
- Properties
- Condition
Lookup Source
We
use a flat file, relational table, or source qualifier for a lookup source.
When you create a Lookup transformation, you can create the lookup source from
the following locations:
- Relational source or target
definition in the repository
- Flat file source or target
definition in the repository
- Table or file that the
Integration Service and PowerCenter Client machine can connect to
- Source qualifier definition in
a mapping
The
lookup table can be a single table, or you can join multiple tables in the same
database using a lookup SQL override. The Integration Service queries the
lookup table or an in-memory cache of the table for all incoming rows into the
Lookup transformation.
The
Integration Service can connect to a lookup table using ODBC or native drivers.
Configure native drivers for optimal performance.
Indexes and a Lookup Table
If
you have privileges to modify the database containing a lookup table, you can
improve lookup initialization time by adding an index to the lookup table. You
can improve performance for very large lookup tables. Since the Integration
Service queries, sorts, and compares values in lookup columns, the index needs
to include every column in a lookup condition.
You
can improve performance by indexing the following types of lookup:
- Cached lookups. You can improve performance by indexing the
columns in the lookup ORDER BY. The session log contains the ORDER BY
clause.
- Uncached lookups. Because the Integration Service issues a SELECT
statement for each row passing into the Lookup transformation, you can
improve performance by indexing the columns in the lookup condition.
Lookup Ports
The
Ports tab contains input and output ports. The Ports tab also includes lookup
ports that represent columns of data to return from the lookup source. An
unconnected Lookup transformation returns one column of data to the calling
transformation in this port. An unconnected Lookup transformation has one
return port.
Ports
|
Type
of Lookup
|
Description
|
I
|
Connected
Unconnected
|
Input
port. Create an input port for each lookup port you want to use in the lookup
condition. You must have at least one input or input/output port in each
Lookup transformation.
|
O
|
Connected
Unconnected
|
Output
port. Create an output port for each lookup port you want to link to another
transformation. You can designate both input and lookup ports as output
ports. For connected lookups, you must have at least one output port. For
unconnected lookups, select a lookup port as a return port (R) to pass a
return value.
|
L
|
Connected
Unconnected
|
Lookup
port. The Designer designates each column in the lookup source as a lookup
(L) and output port (O).
|
R
|
Unconnected
|
Return
port. Use only in unconnected Lookup transformations. Designates the column
of data you want to return based on the lookup condition. You can designate
one lookup port as the return port.
|
The
Lookup transformation also enables an associated expression property that you
configure when you use a dynamic cache. The associated expression property
contains the data to update the lookup cache. It can contain an expression to
update the dynamic cache or it can contain an input port name.
Use
the following guidelines to configure lookup ports:
- If you delete lookup ports from
a flat file lookup, the session fails.
- You can delete lookup ports
from a relational lookup if the mapping does not use the lookup port. This
reduces the amount of memory the Integration Service needs to run the
session.
Lookup Properties
Configure
the lookup properties such as caching and multiple matches on the Lookup
Properties tab. Configure the lookup condition or the SQL statements to query
the lookup table. We can also change the Lookup table name.
When
we create a mapping, we configure the properties for each Lookup
transformation. When we create a session, we can override properties such as
the index and the data cache size for each transformation.
The
following table describes the Lookup transformation properties:
Option
|
Lookup
Type
|
Description
|
Lookup
SQL Override
|
Relational
|
Overrides
the default SQL statement to query the lookup table.
Specifies
the SQL statement you want the Integration Service to use for querying lookup
values. Use with the lookup cache enabled.
|
Lookup
Table Name
|
Pipeline
Relational
|
The
name of the table or the source qualifier from which the transformation looks
up and caches values. When you create the Lookup transformation, choose a
source, target, or source qualifier as the lookup source. You can also import
a table, view, or synonym from another database when you create the Lookup
transformation.
If
you enter a lookup SQL override, you do not need to enter the Lookup Table
Name.
|
Lookup
Source Filter
|
Relational
|
Restricts
the lookups the Integration Service performs based on the value of data in
any port in the Lookup transformation. Use with the lookup cache enabled.
|
Lookup
Caching Enabled
|
Flat
File
Pipeline
Relational
|
Indicates
whether the Integration Service caches lookup values during the session.
When
you enable lookup caching, the Integration Service queries the lookup source
once, caches the values, and looks up values in the cache during the session.
Caching the lookup values can improve session performance.
When
you disable caching, each time a row passes into the transformation, the
Integration Service issues a select statement to the lookup source for lookup
values.
Note: The Integration Service always caches the flat file
lookups and the pipeline lookups.
|
Lookup
Policy on Multiple Match
|
Flat
File
Pipeline
Relational
|
Determines
which rows to return when the Lookup transformation finds multiple rows that
match the lookup condition. Select one of the following values:
|
Lookup
Condition
|
Flat
File
Pipeline
Relational
|
Displays
the lookup condition you set in the Condition tab.
|
Connection
Information
|
Relational
|
Specifies
the database that contains the lookup table. You can define the database in
the mapping, session, or parameter file:
By default, the Designer specifies $Source if you choose a
source table and $Target if you choose a target table when you create the
Lookup transformation. You can override these values in the session
properties.
The
Integration Service fails the session if it cannot determine the type of
database connection.
|
Source
Type
|
Flat
File
Pipeline
Relational
|
Indicates
that the Lookup transformation reads values from a relational table, flat
file, or source qualifier.
|
Tracing
Level
|
Flat
File
Pipeline
Relational
|
Sets
the amount of detail included in the session log.
|
Lookup
Cache Directory Name
|
Flat
File
Pipeline
Relational
|
Specifies
the directory used to build the lookup cache files when you configure the
Lookup transformation to cache the lookup source. Also saves the persistent
lookup cache files when you select the Lookup Persistent option.
By
default, the Integration Service uses the $PMCacheDir directory configured
for the Integration Service.
|
Lookup
Cache Persistent
|
Flat
File
Pipeline
Relational
|
Indicates
whether the Integration Service uses a persistent lookup cache, which
consists of at least two cache files. If a Lookup transformation is
configured for a persistent lookup cache and persistent lookup cache files do
not exist, the Integration Service creates the files during the session. Use
with the lookup cache enabled.
|
Lookup
Data Cache Size Lookup Index Cache Size
|
Flat
File
Pipeline
Relational
|
Default
is Auto. Indicates the maximum size the Integration Service allocates to the
data cache and the index in memory. You can configure a numeric value, or you
can configure the Integration Service to determine the cache size at run
time. If you configure the Integration Service to determine the cache size,
you can also configure a maximum amount of memory for the Integration Service
to allocate to the cache.
If
the Integration Service cannot allocate the configured amount of memory when
initializing the session, it fails the session. When the Integration Service
cannot store all the data cache data in memory, it pages to disk.
Use
with the lookup cache enabled.
|
Dynamic
Lookup Cache
|
Flat
File
Pipeline
Relational
|
Indicates
to use a dynamic lookup cache. Inserts or updates rows in the lookup cache as
it passes rows to the target table.
Use
with the lookup cache enabled.
|
Output
Old Value On Update
|
Flat
File
Pipeline
Relational
|
Use
with dynamic caching enabled. When you enable this property, the Integration
Service outputs old values out of the lookup/output ports. When the
Integration Service updates a row in the cache, it outputs the value that
existed in the lookup cache before it updated the row based on the input
data. When the Integration Service inserts a row in the cache, it outputs
null values.
When
you disable this property, the Integration Service outputs the same values
out of the lookup/output and input/output ports.
This
property is enabled by default.
|
Update
Dynamic Cache Condition
|
Flat
File
Pipeline
Relational
|
An
expression that indicates whether to update dynamic cache. Create an
expression using lookup ports or input ports. The expression can contain
input values or values in the lookup cache. The Integration Service updates
the cache when the condition is true and the data exists in the cache. Use
with dynamic caching enabled. Default is true.
|
Cache
File Name Prefix
|
Flat
File
Pipeline
Relational
|
Use
with persistent lookup cache. Specifies the file name prefix to use with
persistent lookup cache files. The Integration Service uses the file name
prefix as the file name for the persistent cache files it saves to disk.
Enter the prefix. Do not enter .idx or .dat.
You
can enter a parameter or variable for the file name prefix. Use any parameter
or variable type that you can define in the parameter file.
If
the named persistent cache files exist, the Integration Service builds the
memory cache from the files. If the named persistent cache files do not
exist, the Integration Service rebuilds the persistent cache files.
|
Recache
From Lookup Source
|
Flat
File
Pipeline
Relational
|
Use
with the lookup cache enabled. When selected, the Integration Service
rebuilds the lookup cache from the lookup source when it first calls the
Lookup transformation instance.
If
you use a persistent lookup cache, it rebuilds the persistent cache files
before using the cache. If you do not use a persistent lookup cache, it
rebuilds the lookup cache in the memory before using the cache.
|
Insert
Else Update
|
Flat
File
Pipeline
Relational
|
Use
with dynamic caching enabled. Applies to rows entering the Lookup
transformation with the row type of insert. When enabled, the Integration
Service inserts rows in the cache and updates existing rows When disabled,
the Integration Service does not update existing rows.
|
Update
Else Insert
|
Flat
File
Pipeline
Relational
|
Use
with dynamic caching enabled. Applies to rows entering the Lookup
transformation with the row type of update.
When
enabled, the Integration Service updates existing rows, and inserts a row if
it is new. When disabled, the Integration Service does not insert new rows.
|
Datetime
Format
|
Flat
File
|
Click
the Open button to select a datetime format. Define the format and the field
width. Milliseconds, microseconds, or nanoseconds formats have a field width
of 29.
If
you do not select a datetime format for a port, you can enter any datetime
format. Default is MM/DD/YYYY HH24:MI:SS. The Datetime format does not change
the size of the port.
|
Thousand
Separator
|
Flat
File
|
If
you do not define a thousand separator for a port, the Integration Service
uses the properties defined here.
You
can choose no separator, a comma, or a period. Default is no separator.
|
Decimal
Separator
|
Flat
File
|
If
you do not define a decimal separator for a particular field in the lookup
definition or on the Ports tab, the Integration Service uses the properties
defined here.
You
can choose a comma or a period decimal separator. Default is period.
|
Case-Sensitive
String Comparison
|
Flat
File
Pipeline
|
The
Integration Service uses case sensitive string comparisons when performing
lookups on string columns.
For
relational lookups, the case sensitive comparison depends on the database
support.
|
Null
Ordering
|
Flat
File
Pipeline
|
Determines
how the Integration Service orders null values. You can choose to sort null
values high or low. By default, the Integration Service sorts null values
high. This overrides the Integration Service configuration to treat nulls in
comparison operators as high, low, or null.
For
relational lookups, null ordering depends on the database default value.
|
Sorted
Input
|
Flat
File
Pipeline
|
Indicates
whether or not the lookup file data is in sorted order. This increases lookup
performance for file lookups. If you enable sorted input, and the condition
columns are not grouped, the Integration Service fails the session. If the
condition columns are grouped, but not sorted, the Integration
Service processes the lookup as if you did not configure sorted input.
|
Lookup
Source is Static
|
Flat
File
Pipeline
Relational
|
The
lookup source does not change in a session.
|
Pre-build
Lookup Cache
|
Flat
File
Pipeline
Relational
|
Allows
the Integration Service to build the lookup cache before the Lookup
transformation receives the data. The Integration Service can build multiple
lookup cache files at the same time to improve performance.
You
can configure this option in the mapping or the session. The Integration
Service uses the session-level setting if you configure the Lookup transformation
option as Auto.
Configure
one of the following options:
You must configure the number of pipelines that the
Integration Service can build concurrently. Configure the Additional
Concurrent Pipelines for Lookup Cache Creation session property. The
Integration Service can pre-build lookup cache if this property is greater
than zero.
|
Subsecond
Precision
|
Relational
|
Specifies
the subsecond precision for datetime ports.
For
relational lookups, you can change the precision for databases that have an
editable scale for datetime data. You can change subsecond precision for
Oracle Timestamp, Informix Datetime, and Teradata Timestamp datatypes.
Enter
a positive integer value from 0 to 9. Default is 6 microseconds. If you
enable pushdown optimization, the database returns the complete datetime
value, regardless of the subsecond precision setting.
|
Flat file lookups: Configure
lookup location information, such as the source file directory, file name, and
the file type.
Relational lookups: You
can define $Source and $Target variables in the session properties. You can
also override connection information to use the $DBConnectionName or
$AppConnectionName session parameter.
Pipeline lookups: Configure
the lookup source file properties such as the source file directory, file name,
and the file type. If the source is a relational table or application source,
configure the connection information.
Configuring Flat File
Lookups in a Session
When you configure a flat file
lookup in a session, configure the lookup source file properties on the
Transformation View of the Mapping tab. Choose the Lookup transformation and
configure the flat file properties in the session properties for the
transformation.
The following table describes the
session properties you configure for flat file lookups:
- Lookup Source File Directory
will be $PMLookupFileDir/<your_project_foldername>
(default $PMLookupFileDir)
- Lookup Source Filename you can
either given the lookup file name or use parameter $LookupFileName
($Lookup is prefix to lookup file name).
- Lookup Source Filetype will
Indicates whether the lookup source file contains the source data or a
list of files with the same file properties. Choose Direct if the lookup
source file contains the source data. Choose Indirect if the lookup source
file contains a list of files.
Configuring Relational
Lookups in a Session
When you configure a relational
lookup in a session, configure the connection for the lookup database on the
Transformation View of the Mapping tab. Choose the Lookup transformation and
configure the connection in the session properties for the transformation.
Choose from the following options to
configure a connection for a relational Lookup transformation:
- Choose a relational or
application connection.
- Configure a database connection
using the $Source or $Target connection variable.
- Configure the session
parameter $DBConnectionName or $AppConnectionName,
and define the session parameter in a parameter file.
Configuring Pipeline
Lookups in a Session
When you configure a pipeline Lookup
in a session, configure the location of lookup source file or the connection
for the lookup table on the Sources node of the Mapping tab. Choose the Source
Qualifier that represents the lookup source.
Lookup Query
The Integration Service queries the
lookup based on the ports and properties you configure in the Lookup
transformation. The Integration Service runs a default SQL statement when the
first row enters the Lookup transformation. If you use a relational lookup or a
pipeline lookup against a relational table, you can customize the default query
with the Lookup SQL Override property.
You can restrict the rows that a
Lookup transformation retrieves from the source when it builds the lookup
cache. Configure the Lookup Source Filter.
If you configure both the Lookup SQL
Override and the Lookup Source Filter properties, the Integration Service
ignores the Lookup Source Filter property.
Default Lookup Query
- The default lookup query
contains the following statements:
- SELECT. The SELECT statement includes all the lookup
ports in the mapping. You can view the SELECT statement by generating SQL
using the Lookup SQL Override property. Do not add or delete any columns
from the default SQL statement.
- ORDER BY. The ORDER BY clause orders the columns in the
same order they appear in the Lookup transformation. The Integration
Service generates the ORDER BY clause. You cannot view this when you
generate the default SQL using the Lookup SQL Override property.
Overriding the ORDER BY Clause
By
default, the Integration Service generates an ORDER BY clause for a cached
lookup. The ORDER BY clause contains all lookup ports. To increase performance,
you can suppress the default ORDER BY clause and enter an override ORDER BY
with fewer columns.
Note: If you use pushdown optimization, you cannot override
the ORDER BY clause or suppress the generated ORDER BY clause with a comment
notation.
The
Integration Service always generates an ORDER BY clause, even if you enter one
in the override. Place two dashes ‘--’ after the ORDER BY override to suppress
the generated ORDER BY clause. For example, a Lookup transformation uses the
following lookup condition:
ITEM_ID
= IN_ITEM_ID PRICE <= IN_PRICE
The
Lookup transformation includes three lookup ports used in the mapping, ITEM_ID,
ITEM_NAME, and PRICE. When you enter the ORDER BY clause, enter the columns in
the same order as the ports in the lookup condition. You must also enclose all
database reserved words in quotes. Enter the following lookup query in the
lookup SQL override:
SELECT
ITEMS_DIM.ITEM_NAME, ITEMS_DIM.PRICE, ITEMS_DIM.ITEM_ID FROM ITEMS_DIM ORDER BY
ITEMS_DIM.ITEM_ID, ITEMS_DIM.PRICE --
Lookup Condition
The
Integration Service finds data in the lookup source with a lookup condition.
The lookup condition is similar to the WHERE clause in an SQL query. When you
configure a lookup condition in a Lookup transformation, you compare the value
of one or more columns in the source data with values in the lookup source or
cache.
Use
the following guidelines when you enter a condition for a Lookup
transformation:
- The datatypes for the columns
in a lookup condition must match.
- You must enter a lookup condition
in all Lookup transformations.
- Use one input port for each
lookup port in the lookup condition. Use the same input port in more than
one condition in a transformation.
- When you enter multiple
conditions, the Integration Service evaluates each condition as an AND,
not an OR. The Integration Service returns rows that match all the
conditions you configure.
- If you include multiple
conditions, enter the conditions in the following order to optimize lookup
performance:
- Equal to (=)
- Less than (<), greater than
(>), less than or equal to (<=), greater than or equal to (>=)
- Not equal to (!=)
- The Integration Service matches
null values. For example, if an input lookup condition column is NULL, the
Integration Service evaluates the NULL equal to a NULL in the lookup.
- If you configure a flat file
lookup for sorted input, the Integration Service fails the session if the
condition columns are not grouped. If the columns are grouped, but not
sorted, the Integration Service processes the lookup as if you did not configure
sorted input.
The
Integration Service processes lookup matches differently depending on whether
you configure the transformation for a dynamic cache or an uncached or static
cache.
Uncached or Static Cache
Use
the following guidelines when you configure a Lookup transformation that has a
static lookup cache or an uncached lookup source:
- Use the following operators
when you create the lookup condition:
=, >,
<, >=, <=, !=
If
you include more than one lookup condition, place the conditions in the
following order to optimize lookup performance:
- Equal to (=)
- Less than (<), greater than (>), less than or
equal to (<=), greater than or equal to (>=)
- Not equal to (!=)
For
example, create the following lookup condition:
ITEM_ID = IN_ITEM_ID PRICE <= IN_PRICE
- The input value must meet all
conditions for the lookup to return a value.
The
condition can match equivalent values or supply a threshold condition. For
example, you might look for customers who do not live in California, or
employees whose salary is greater than $30,000. Depending on the nature of the
source and condition, the lookup might return multiple values.
Dynamic Cache
If
you configure a Lookup transformation to use a dynamic cache, you can use only
the equality operator (=) in the lookup condition.
Handling Multiple Matches
The
Lookup transformation finds values based on the condition you configure in the
transformation. If the lookup condition is not based on a unique key, or if the
lookup source is denormalized, the Integration Service might find multiple
matches in the lookup source or the lookup cache.
You
can configure a Lookup transformation to handle multiple matches in the
following ways:
- Use the first matching value,
or use the last matching value. We
can configure the transformation to return the first matching value or the
last matching value. The first and last values are the first value and
last value found in the lookup cache that match the lookup condition. When
you cache the lookup source, the Integration Service generates an ORDER BY
clause for each column in the lookup cache to determine the first and last
row in the cache. The Integration Service then sorts each lookup source
column in ascending order.
The Integration Service sorts numeric columns in ascending
numeric order such as 0 to 10. It sorts date/time columns from January to
December and from the first of the month to the end of the month. The
Integration Service sorts string columns based on the sort order configured for
the session.
- Use any matching value. We can configure the Lookup transformation to return
any value that matches the lookup condition. When we configure the Lookup
transformation to return any matching value, the transformation returns
the first value that matches the lookup condition. The transformation
creates an index based on the key ports instead of all Lookup
transformation ports. When you use any matching value, performance can
improve because the process of indexing rows is simpler.
- Use all values. The Lookup transformation returns all matching rows.
To use this option, you must configure the Lookup transformation to return
all matches when you create the transformation. The transformation becomes
an active transformation. You cannot change the mode between passive and
active after you create the transformation.
- Return an error. When the Lookup transformation uses a static
cache or no cache, the Integration Service marks the row as an error. The
Lookup transformation writes the row to the session log by default, and
increases the error count by one. When the Lookup transformation has a
dynamic cache, the Integration Service fails the session when it
encounters multiple matches. The session fails while the Integration
Service is caching the lookup table or looking up the duplicate key
values. Also, if you configure the Lookup transformation to output old
values on updates, the Lookup transformation returns an error when it
encounters multiple matches. The transformation creates an index based on
the key ports instead of all Lookup transformation ports.
Lookup Caches
We
can configure a Lookup transformation to cache the lookup file or table. The
Integration Service builds a cache in memory when it processes the first row of
data in a cached Lookup transformation. It allocates memory for the cache based
on the amount you configure in the transformation or session properties. The
Integration Service stores condition values in the index cache and output
values in the data cache. The Integration Service queries the cache for each
row that enters the transformation.
The
Integration Service also creates cache files by default in the $PMCacheDir. If
the data does not fit in the memory cache, the Integration Service stores the
overflow values in the cache files. When the session completes, the Integration
Service releases cache memory and deletes the cache files unless you configure
the Lookup transformation to use a persistent cache.
When
configuring a lookup cache, you can configure the following options:
- Persistent cache
- Recache from lookup source
- Static cache
- Dynamic cache
- Shared cache
- Pre-build lookup cache
Note: You can use a dynamic cache for relational or flat
file lookups.
Rules and Guidelines for Returning Multiple Rows
Use
the following rules and guidelines when you configure the Lookup transformation
to return multiple rows:
- The Integration Service caches
all rows from the lookup source for cached lookups.
- You can configure an SQL
override for a cached or uncached lookup that returns multiple rows.
- You cannot enable dynamic cache
for a Lookup transformation that returns multiple rows.
- You cannot return multiple rows
from an unconnected Lookup transformation.
- You can configure multiple
Lookup transformations to share a named cache if the Lookup transformations
have matching caching lookup on multiple match policies.
- An Lookup transformation that
returns multiple rows cannot share a cache with a Lookup transformation
that returns one matching row for each input row.
Lookup Caches Overview
We
can configure a Lookup transformation to cache the lookup table. The
Integration Service builds a cache in memory when it processes the first row of
data in a cached Lookup transformation. It allocates memory for the cache based
on the amount you configure in the transformation or session properties. The
Integration Service stores condition values in the index cache and output
values in the data cache. The Integration Service queries the cache for each
row that enters the transformation.
The
Integration Service also creates cache files by default in the $PMCacheDir. If
the data does not fit in the memory cache, the Integration Service stores the
overflow values in the cache files. When the session completes, the Integration
Service releases cache memory and deletes the cache files unless you configure
the Lookup transformation to use a persistent cache.
If
you use a flat file or pipeline lookup, the Integration Service always caches
the lookup source. If you configure a flat file lookup for sorted input, the
Integration Service cannot cache the lookup if the condition columns are not
grouped. If the columns are grouped, but not sorted, the Integration Service
processes the lookup as if you did not configure sorted input.
When
you configure a lookup cache, you can configure the following cache settings:
- Building caches: We can configure the session to build caches
sequentially or concurrently. When you build sequential caches, the
Integration Service creates caches as the source rows enter the Lookup
transformation. When you configure the session to build concurrent caches,
the Integration Service does not wait for the first row to enter the
Lookup transformation before it creates caches. Instead, it builds
multiple caches concurrently.
- Persistent cache: We can save the lookup cache files and reuse them
the next time the Integration Service processes a Lookup transformation
configured to use the cache.
- Recache from source: If the persistent cache is not synchronized with
the lookup table, you can configure the Lookup transformation to rebuild
the lookup cache.
- Static cache: We can configure a static, or read-only, cache
for any lookup source. By default, the Integration Service creates a
static cache. It caches the lookup file or table and looks up values in
the cache for each row that comes into the transformation. When the lookup
condition is true, the Integration Service returns a value from the lookup
cache. The Integration Service does not update the cache while it
processes the Lookup transformation.
- Dynamic cache: To cache a table, flat file, or source definition
and update the cache, configure a Lookup transformation with dynamic
cache. The Integration Service dynamically inserts or updates data in the
lookup cache and passes the data to the target. The dynamic cache is synchronized
with the target.
- Shared cache: We can share the lookup cache between multiple
transformations. We can share an unnamed cache between transformations in
the same mapping. We can share a named cache between transformations in
the same or different mappings. Lookup transformations can share unnamed
static caches within the same target load order group if the cache sharing
rules match. Lookup transformations cannot share dynamic cache within the
same target load order group.
When
you do not configure the Lookup transformation for caching, the Integration
Service queries the lookup table for each input row. The result of the Lookup
query and processing is the same, whether or not you cache the lookup table.
However, using a lookup cache can increase session performance. Optimize
performance by caching the lookup table when the source table is large.
Note: The Integration Service uses the same transformation
logic to process a Lookup transformation whether you configure it to use a
static cache or no cache. However, when you configure the transformation to use
no cache, the Integration Service queries the lookup table instead of the
lookup cache.
Cache Comparison
The
following table compares the differences between an uncached lookup, a static
cache, and a dynamic cache:
Uncached
|
Static
Cache
|
Dynamic
Cache
|
We
cannot insert or update the cache.
|
We
cannot insert or update the cache.
|
We
can insert or update rows in the cache as you pass rows to the target.
|
We
cannot use a flat file or pipeline lookup.
|
Use
a relational, flat file, or pipeline lookup.
|
Use
a relational, flat file, or Source Qualifier lookup.
|
When
the condition is true, the Integration Service returns a value from the
lookup table or cache.
When
the condition is not true, the Integration Service returns the default value
for connected transformations and NULL for unconnected transformations.
|
When
the condition is true, the Integration Service returns a value from the
lookup table or cache.
When
the condition is not true, the Integration Service returns the default value
for connected transformations and NULL for unconnected transformations.
|
When
the condition is true, the Integration Service either updates rows in the
cache or leaves the cache unchanged, depending on the row type. This indicates
that the row is in the cache and target table. You can pass updated rows to a
target.
When
the condition is not true, the Integration Service either inserts rows into
the cache or leaves the cache unchanged, depending on the row type. This
indicates that the row is not in the cache or target. You can pass inserted
rows to a target table.
|
Building Connected Lookup Caches
The
Integration Service can build lookup caches for connected Lookup
transformations in the following ways:
- Sequential caches. The Integration Service builds lookup caches
sequentially. The Integration Service builds the cache in memory when it
processes the first row of the data in a cached lookup transformation.
- Concurrent caches. The Integration Service builds lookup caches concurrently.
It does not need to wait for data to reach the Lookup transformation.
Note: The Integration Service builds caches for unconnected
Lookup transformations sequentially regardless of how you configure cache
building. If you configure the session to build concurrent caches for an
unconnected Lookup transformation, the Integration Service ignores this setting
and builds unconnected Lookup transformation caches sequentially.
How
to Select/Import Lookup table?
We
can select source/target definition as lookup, if it already exist in the
repository. If not we can import it from relational or Flat File.
1.
Click on Lookup Icon highlighted below:

2.
Click on Workspace

1.
Sample Mapping wtih Connected Lookup:
Create
a mapping using EMP table and do lookup on DEPT table to get DNAME and LOC
using DEPTNO.
1.Connect
and Open the folder if not already opened.
2.
Select Tools --> Mapping Designer

3.
Select Mappings --> Create
It
will pop-up "Mapping Name". Enter the mapping name of your
choice" and Click on 'OK'. Example: m_emp_dept_lookup

4.
Drag the Source and Target definitions into workspace if they are already
exist. If not click here to know how to create or import Table definitions.

5.
Select 'Transformation' from Menu --> Create

a)
That will appear you 'Select the transformation type to create:'

b)
Select 'Lookup' from drop down and 'Enter a new name for this transformation:'
as "lkp_DEPT"
c)
Click 'Create' then it will pop-up 'Select Lookup table for Lookup
Transformation'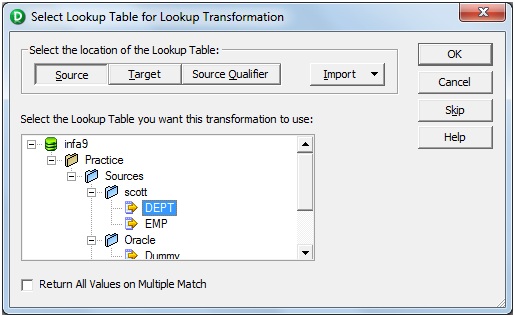
d)
Select the Source definition: DEPT then click 'OK' and Done.

OR
a)
Click on Lookup Transformation icon marked below in below snapshot.

b)
Click in the workspace in Mapping Designer.
c)
Select Lookup table location: 'Source'
d)
Select Definition: DEPT and Click 'OK'
e)
Select LKPTRANS in workspace and Right Click --> Edit.
f)
In Transformation tab --> Click on 'Rename' highlighted above which will
pop-up 'Rename Transformation'. Enter the Transformation Name:
"lkp_DEPT"
g)
Click on 'OK'
h)
Click on 'Apply' and 'OK'.
6).
Drag required (all) ports from 'SQ_EMP' Source Qualifier to 'lkp_DEPT' lookup
Transformation.

7)
Select 'lkp_DEPT' Lookup Transformation and Right Click --> Edit -->
Ports Tab.
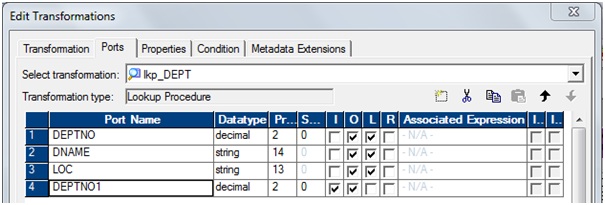
a)
Rename 'DEPTNO1' to 'IN_DEPTNO'

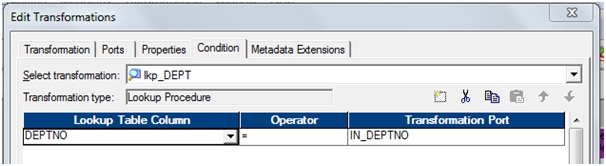
b)
Go to 'Condition' tab: Add a port and then match condition below.
c) Go to 'Properties' tab: Check the Lookup Condition'

d)
Click on 'Apply' and Click on 'OK'.

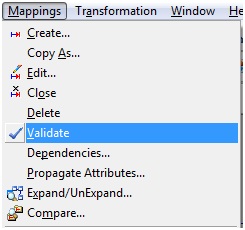
9)
Select 'Mapping' from Menu --> Validate.
10)
Select 'Repository' from Menu --> Save.

2.
Sample Mapping wtih Unconnected Looup:
Create
a mapping using EMP table and do lookup on DEPT table to get DNAME using
DEPTNO. (Unconnected lookup will return only single value for each row).
1.Connect
and Open the folder if not already opened.
2.
Select Tools --> Mapping Designer
3.
Select Mappings --> Create
It
will pop-up "Mapping Name". Enter the mapping name of your
choice" and Click on 'OK'. Example: m_emp_dept_unconnlookup

4.
Drag the Source and Target definitions into workspace if they are already
exist. If not click here to know how to create or import Table definitions.
5.
Select 'Transformation' from transformations menu
a) Click on Lookup
Transformation icon marked below in below snapshot.
b)
Click in the workspace in Mapping Designer.
c)
Select Lookup table location: 'Source'
d)
Select Definition: DEPT and Click 'OK'
e)
Select LKPTRANS in workspace and Right Click --> Edit.
f)
In Transformation tab --> Click on 'Rename' highlighted above which will
pop-up 'Rename Transformation'. Enter the Transformation Name:
"lkp_DEPT"
g)
Click on 'OK'
h)
Click on 'Apply' and 'OK'.

a)
Add a port 'IN_DEPTNO'

b)
Select 'DNAME' as return port.

d)
Go to 'Properties' tab: Check the Lookup Condition'
e)
Click on 'Apply' and Click on 'OK'.

8)
Select 'exp_get_dname' expression, edit it and add Output port 'DNAME'.


Note:
Unconnected lookup can be called ":LKP"<unconnected_lookupname>
and sequence input arguments.

11)
Drag required port from 'exp_get_dname' expression to 'Employee_Dept' target
table.

Note:
1.
We can override 'Lookup Sql Override'
2.
We can override 'Lookup table name'
3. We can add 'Lookup Source Filter'
Tips:
- The session fails if you
include large object ports in a WHERE clause.
- If you use pushdown
optimization, you cannot override the ORDER BY clause or suppress the
generated ORDER BY clause with a comment notation.
- The reserved words file,
reswords.txt, is a file that you create and maintain in the Integration
Service installation directory. The Integration Service searches this file
and places quotes around reserved words when it executes SQL against
source, target, and lookup databases.
- You cannot use subqueries in
the SQL override for uncached lookups.
- You can use a dynamic cache for
relational or flat file lookups.
- Avoid syntax errors when you
enter expressions by using the point-and-click method to select functions
and ports.
- You can manually add the lookup ports instead of importing a definition. You can choose which lookup ports are also output ports.
Nice Explanation :)
ReplyDeletenice exp
ReplyDeletevery good work thx :)
ReplyDeletereally nice work! keep it up
ReplyDeletethanq gowtham sir wonderfull blog
ReplyDeletehi sir i have one doubt without using common column how we get related values EX in EMP THERE is no DEPTNO and i want Dname from Dept table please reply gowtham
ReplyDeletehi sir i have one doubt without using common column how we get related values EX in EMP THERE is no DEPTNO and i want Dname from Dept table please reply gowtham
ReplyDeleteExcellent and Nice explanation
ReplyDeleteNice thanks to sharing informatica reference I am john lives in Chennai. I am technology freak.
ReplyDeleteI did informatica Training in Chennai at besant technology. This is useful for me to make a bright career in IT field. besanttechnologies reviews |
besanttechnologies reviews | besanttechnologies reviews | besanttechnologies reviews
Nice explanation ,keep it up! Java Training Chennai
ReplyDeleteThanks gowtham, nice articles to your sites Java Training in Chennai
ReplyDeleteThanks for sharing the wonderful information.Its really useful..!!
ReplyDeleteCcna Training in Chennai | Dot net training in chennai
Learned something new . i am a newbie hope it will work for me! thanks.
ReplyDeleteCloud Computing Training in Chennai , ios Training in Chennai
very nice blogs!!! i have to learning for lot of information for this sites...Sharing for wonderful information.Thanks for sharing this valuable information to our vision. You have posted a trust worthy blog keep sharing.
ReplyDeleteInformatica Training in Chennai
I am reading your post from the beginning, it was so interesting to read & I feel thanks to you for posting such a good blog, keep updates regularly.
ReplyDeleteinformatica training in chennai
This is very good information
ReplyDeleteinformatica online training, informatica training in bangalore, informaitca training
How to populate the data in to the target, if the lookup returns 3 matching values, how to insert all these data into the target?......... PHP Training in Chennai
ReplyDeleteHow to populate the data in to the target, if the lookup returns 3 matching values, how to insert all these data into the target? Pega Training in Chennai
ReplyDeleteThe lookup tranformation can be tuned using cached or uncached lookups. See the below mathematical approach to determine the best way to do so.
ReplyDeleteN = Number of records coming from source (For the purpose of simplicity, let’s assume N also equals to the number of times the lookup will be called)
M = Number of records retrieved from the Lookup query
t = time required to retrieve a single record from database based on the Lookup query
T = time required to retrieve all the records from database based on the Lookup query = M * t
L = Time required to build the lookup index cache for cached lookup = f(N)
C = Network Time required to do one round trip for data fetch from database
In case of an uncached lookup, total time required will be:
T uncached = N * t + N * C
In case of a cached lookup, total time required to build the cache will be:
Tcached = T + L + C
In the above equation we can put L = f(N) and since C is generally very small number, we can ignore C and rewrite the above equation as –
Tcached = T + f(N)
Now if we assume that the database table has INDEX defined upon it and the index is being used while retrieving records from database then, we can further assume –
T = M * t
Replacing the above value in our earlier equation for Tcached we get –
Tcached= M * t + f(N)
We should use uncached lookup if –
Tcached > Tuncached
=> M * t + f(N) > N * t + N * C
Dividing all sides by N, we get –
C + t < (M/N)*t + f(N)/N
For a given Informatica and database setup, C, t & f(N) are fixed.
So the above equation is more likely to be true if (M/N) ratio is on higher side, i.e. N << M – that is – number of records coming from source is considerably less than number of records present in the lookup table (Refer back to point no. 1 in the discussion above).
Similarly, if N >> M – that is number of records coming from source is considerably high than the number of records present in lookup table, then we should use cached lookup.
PHP Training in Chennai
How will you access a flat file which is not in Informatica server location? ... Is look up active or passive and how? .... Pega Training in Chennai
ReplyDeleteI have one doubt. Can a named persistent cache lookup be accessed among sessions of different workflow? eg. in wk1 there is a session having a mapping with a persistent named cache so can a session in wk2 access it?
ReplyDeleteReally awesome blog. Your blog is really useful for me. Thanks for sharing this informative blog. Keep update your blog.
ReplyDeleteSAS Training In Chennai
Really awesome blog.
ReplyDeleteamazon-web-services training in chennai
Thanks for sharing this informative blog.
ReplyDeleteinformix training in chennai
This is Great and very useful advice with in this post. Thank you.
ReplyDeletec,c++ training in chennai
Thank you so much for sharing... lucky patcher tutorial
ReplyDeleteThank you so much for excellent information and useful tips...
ReplyDeleteI have read your blog from the beginning, it gives lot of information to me. Keep blogging like this.
ReplyDeleteCCNA Training in Chennai | CCNA course in Chennai
Excellent blog, I have learned a lot about Informatica. Keep up the good work and share more like this.
ReplyDeleteInformatica Training in Chennai | Informatica Training institutes in Chennai
I read your blog it's really good, thanks for sharing valuable information with us.
ReplyDeleteExcellent Article, Nice to read your article, very informative.
Excellent article Top AC mechanics Professional Camera sellers ChennaiCatering Service in ChennaiTop Educational Institute Chennai
Excellent Article
swimmingpool contractor chennai
swimmingpool equipment dealer chennai
swimmingpool consultant chennai
I am reading ur post from the beginning, it was so interesting to read & i feel thanks to you for posting such a good blog, keep updates regularly.
ReplyDeleteembedded c training in chennai | embedded system design training in chennai
Useful post to me.thank you for sharing
ReplyDeleteFinal Year Robotics Projects Chennai | Final Year Vlsi Projects Chennai.
Thanks For sharing the blog!!!
ReplyDeleteembedded systems and robotics training in chennai
An interesting topic with great examples, keep updating your knowledge with us.
ReplyDeleteSelenium Training in Chennai
selenium Testing Training
iOS Training in Chennai
iOS Training Institutes in Chennai
Best JAVA Training in Chennai
JAVA Training
Nice information, valuable and excellent design, as share good stuff with good ideas and concepts, lots of great information and inspiration, both of which I need, thanks to offer such a helpful information here.
ReplyDeletepython course institute in bangalore | python Course institute in bangalore| python course institute in bangalore
Great post! I am actually getting ready to across this information, It’s very helpful for this blog.Also great with all of the valuable information you have Keep up the good work you are doing well.
ReplyDeleteOnline DevOps Certification Course - Gangboard
Really it was an awesome article. very interesting to read.
ReplyDeleteThanks for sharing.
Tableau Training in Velachery
Tableau Courses in Velachery
Tableau Training in Tambaram
Tableau Courses in Tambaram
Tableau Training in Adyar
Tableau Courses in Adyar
This blog is more effective and it is very much useful for me.
ReplyDeletewe need more information please keep update more.
android training institutes in bangalore
Android Course in Anna Nagar
Android Courses in T nagar
Android Training Institutes in OMR
Learned a lot from your blog. Good creation and hats off to the creativity of your mind. Share more like this.
ReplyDeleteBlockchain Training Institutes in Chennai
Blockchain course in Adyar
AWS Training in Chennai
AWS Certification in Chennai
ccna course in Chennai
Python course in Chennai
I found this informative and interesting blog so i think so its very useful and knowledge able.I would like to thank you for the efforts you have made in writing this article.
ReplyDeletepython training in chennai | python training in chennai | python training in bangalore
I found your blog while searching for the updates, I am happy to be here. Very useful content and also easily understandable providing.. Believe me I did wrote an post about tutorials for beginners with reference of your blog.
ReplyDeleteJava training in Bangalore | Java training in Electronic city
Java training in Chennai | Java training institute in Chennai | Java course in Chennai
Java training in USA
Java training in Bangalore | Java training in Indira nagar
Hello! This is my first visit to your blog! We are a team of volunteers and starting a new initiative in a community in the same niche. Your blog provided us useful information to work on. You have done an outstanding job.
ReplyDeleteAWS Training in Bangalore | Amazon Web Services Training in Bangalore
AWS Interview Questions And Answers
Learn Amazon Web Services Tutorial |AWS Tutorials For Beginners
Amazon Web Services Training in OMR , Chennai | Best AWS Training in OMR,Chennai
AWS Training in Chennai |Best Amazon Web Services Training in Chennai
This comment has been removed by the author.
ReplyDeleteThe knowledge of technology you have been sharing thorough this post is very much helpful to develop
ReplyDeleteangularjs interview questions and answers
angularjs Training in bangalore
angularjs Training in bangalore
angularjs Training in chennai
automation anywhere online Training
angularjs interview questions and answers
new idea. here by i also want to share this.
Whoa! I’m enjoying the template/theme of this website. It’s simple, yet effective. A lot of times it’s very hard to get that “perfect balance” between superb usability and visual appeal. I must say you’ve done a very good job with this.
ReplyDeleteAWS Training in Velachery | Best AWS Course in Velachery,Chennai
Best AWS Training in Chennai | AWS Training Institutes |Chennai,Velachery
Amazon Web Services Training in Anna Nagar, Chennai |Best AWS Training in Anna Nagar, Chennai
Amazon Web Services Training in OMR , Chennai | Best AWS Training in OMR,Chennai
I believe that your blog will surely help the readers who are really in need of this vital piece of information. Waiting for your updates.
ReplyDeleteBest English Speaking Course in Mumbai
English Classes in Mumbai
Best Spoken English Classes in Mumbai
English Speaking Training Center in Mumbai
Spoken English Coaching Institute in Mumbai
Best English Classes in Mumbai
Best English Speaking Training near me
Very useful blog thanks for sharing
ReplyDeleteaws training institute in chennai
Amazing post thanks for the blog
ReplyDeleteccna training in chennai
Awesome Writing. Extra-Ordinary piece of work. Waiting for your future updates.
ReplyDeleteData Analytics Courses in Chennai
Big Data Analytics Courses in Chennai
Big Data Analytics Training in Chennai
Data Analytics Training in Chennai
Data Analytics Courses in Velachery
Data Analytics Courses in T Nagar
Great post! This is very useful for me and gain more information, Thanks for sharing with us.
ReplyDeleteArticle submission sites
Education
Thanks for sharing such a great blog Keep posting..
ReplyDeleteCCNA Training in Gurgaon
CCNA Training institute in Gurgaon
It’s really great information for becoming a better Blogger. Keep sharing, Thanks...
ReplyDeleteLearn Hadoop Training from the Industry Experts we bridge the gap between the need of the industry. Softgen Infotech provide the Best Hadoop Training in Bangalore with 100% Placement Assistance. Book a Free Demo Today.
Big Data Analytics Training in Bangalore
Tableau Training in Bangalore
Data Science Training in Bangalore
Workday Training in Bangalore
i loved your informative article.
ReplyDeleteNebosh courses in Chennai
Nebosh HSW Course in Chennai
Nebosh course in Chennai
Nebosh HSL course in Chennai
Nebosh
Nebosh Process Safety Management course
Attend The Data Science Courses Bangalore From ExcelR. Practical Data Science Courses Bangalore Sessions With Assured Placement Support From Experienced Faculty. good work
ReplyDeleteAi & Artificial Intelligence Course in Chennai
PHP Training in Chennai
Ethical Hacking Course in Chennai Blue Prism Training in Chennai
UiPath Training in Chennai
Nice blog, I hope really enjoyed while reading blog here. thanks for sharing such a informative information.
ReplyDeletePHP Online Training
PHP Online Course
PHP Online Training in chennai
Excellent and Job Oriented training on Bigdata andalysis Course provided by Real Time Experts. Thanks for immediate Placement in Laser Technologies
ReplyDeleteTeradata Training in Bangalore
no deposit bonus forex 2021 - takipçi satın al - takipçi satın al - takipçi satın al - takipcialdim.com/tiktok-takipci-satin-al/ - instagram beğeni satın al - instagram beğeni satın al - google haritalara yer ekleme - btcturk - tiktok izlenme satın al - sms onay - youtube izlenme satın al - google haritalara yer ekleme - no deposit bonus forex 2021 - tiktok jeton hilesi - tiktok beğeni satın al - binance - takipçi satın al - uc satın al - finanspedia.com - sms onay - sms onay - tiktok takipçi satın al - tiktok beğeni satın al - twitter takipçi satın al - trend topic satın al - youtube abone satın al - instagram beğeni satın al - tiktok beğeni satın al - twitter takipçi satın al - trend topic satın al - youtube abone satın al - instagram beğeni satın al - tiktok takipçi satın al - tiktok beğeni satın al - twitter takipçi satın al - trend topic satın al - youtube abone satın al - instagram beğeni satın al - perde modelleri - instagram takipçi satın al - instagram takipçi satın al - cami avizesi - marsbahis
ReplyDeleteAmerican shorthair kitten
ReplyDeleteAmerican shorthair cat
Jump into an immense learning experience of DevOps Training in Chennai from Infycle Technologies, the finest software training Institute in Chennai. Also, an excellent place to learn other technical courses like Cyber Security, Graphic Design and Animation, Block Security, Java, Cyber Security, Oracle, Python, Big data, Azure, Python, Manual and Automation Testing, DevOps, Medical Coding etc., and here we provide well-experienced trainers with excellent training to the freshers. And we also provide 100+ Live Practical Sessions with Real-Time scenarios which helps the students in learning the technical stuff easily and they are able to get through interviews in top MNC’s with an amazing package. for more queries call us on 7504633633, 7502633633.
ReplyDeleteAhaa, its nice dialogue about this piece of writing at this place at this webpage,
ReplyDeleteI have read all that, so at this time me also commenting here.
havanese dogs for sale
Hi, I do believe this is a great website. I stumbledupon it ;) I am going to revisit yet
again since I book-marked it. Money and freedom is the greatest way to
change, may you be rich and continue to help other people.
havanese puppies for sale
I used to be suggested this website by means of my cousin. I’m now not sure whether
this submit is written by him as nobody else know such detailed approximately my problem.
You’re incredible! Thanks!
teacup havanese puppy
Pisces p100 miner for sale
ReplyDeletehntcryptominer for sale
Thanks for sharing Valuable Information. Nice Blog
ReplyDeleteInformatica Cloud Training Course Online
Informatica Cloud certification Training
This post is so useful and informative keep updating with more information.....
ReplyDeleteData Science Overview
Data Science Courses Eligibility
This comment has been removed by the author.
ReplyDeleteperde modelleri
ReplyDeleteMobil Onay
Türk Telekom Mobil Ödeme Bozdurma
https://nftnasilalinir.com
ankara evden eve nakliyat
Trafik sigortasi
dedektör
web sitesi kurma
ask kitaplari
smm panel
ReplyDeletesmm panel
İŞ İLANLARI BLOG
İnstagram Takipçi Satın Al
Hırdavatçı Burada
Https://www.beyazesyateknikservisi.com.tr/
servis
tiktok jeton hilesi
ataşehir daikin klima servisi
ReplyDeletependik arçelik klima servisi
tuzla samsung klima servisi
maltepe samsung klima servisi
kadıköy samsung klima servisi
maltepe mitsubishi klima servisi
kadıköy mitsubishi klima servisi
kartal vestel klima servisi
ümraniye vestel klima servisi
360DigiTMG is India's number one Data Science Training Institute. Avail of the best training from professional trainers with a world-class curriculum, LMS Access, real-time projects, and assignments that will help you grab your dream job.
ReplyDeleteData Science Course in Bangalore
Thanks for information
ReplyDeleteCongratulations on your article, it was very helpful and successful. fed6d7f98c7d61ce1b9dbd8abe447ea9
ReplyDeletenumara onay
website kurma
website kurma
Thank you for your explanation, very good content. 1f818d43aa79642193d5af78b49dfb07
ReplyDeletealtın dedektörü
Thanks for sharing this useful blogs
ReplyDeletebancruptcy lawyer near me
bankruptcy lawer near me
Thanks for sharing this valuable content
ReplyDeletebankruptcy lawer near me
bank ruptcy lawyers near me
Good text Write good content success. Thank you
ReplyDeletetipobet
kralbet
kibris bahis siteleri
betpark
slot siteleri
bonus veren siteler
poker siteleri
betmatik
Hi,
ReplyDeleteThis is really a nice blog by you. I really appreciate your efforts for this blog. Keep it up and keep posting such blogs.
There is one language which is most commonly used and that everyone knows after their mother tongue is English. English is one of the most spoken languages in the world. But it is seen that most of the people hesitate to speak English fluently as they didn’t get the necessary environment to learn english. This is because most of the people take online spoken english classes to learn to speak English.
What is a chemical reaction?
Sms onay tr satın al
ReplyDeleteThanks for sharing beautiful content. I got information from your blog.keep sharing
ReplyDeletebetmatik
ReplyDeletekralbet
betpark
mobil ödeme bahis
tipobet
slot siteleri
kibris bahis siteleri
poker siteleri
bonus veren siteler
1CSY3
Thanks for your marvelous posting! I seriously enjoyed reading it, you will be a great author.
ReplyDeleteI will make sure to bookmark your blog and may come back later in life. I want to encourage continue your great posts, I have one more innformation related with roblox..Visit here
This comment has been removed by the author.
ReplyDeleteExperience the accelerated healing properties of aloe vera. Explore how aloe vera speeds up the healing process and learn how it can promote faster recovery from wounds, burns, and other skin ailments.
ReplyDeleteUncover the scientific evidence behind aloe vera's healing abilities. Explore the healing properties of aloe vera and learn how its natural compounds contribute to its remarkable therapeutic effects.
Discover how aloe vera helps with inflammation. Explore the anti-inflammatory benefits of aloe vera and its potential for reducing inflammation in various conditions, providing relief and promoting overall well-being.
Explore the antimicrobial properties of aloe vera. Learn how aloe vera helps with infections and its ability to combat harmful bacteria, making it a valuable natural remedy for various infections.
The "Informatica Complete Reference" serves as a comprehensive resource for building a commenting website. Informatica, a leading data integration and management software, best cameras for photography, provides a wealth of tools and functionalities that can be leveraged to develop a robust and efficient commenting system.
ReplyDeleteThe Informatica platform offers a wide range of features that are relevant to building a commenting website. These include data integration capabilities, real-time data processing, data quality management, and data governance. Leveraging these features allows developers to establish a solid foundation for the commenting website, ensuring that data is seamlessly integrated, processed, and maintained with high quality.
In addition to the core features, the Informatica Complete Reference provides in-depth documentation, best practices, and practical examples. This comprehensive resource enables developers to gain a deep understanding of Informatica's capabilities and how they can be applied to the specific requirements of a commenting website. From designing data models to implementing complex transformations and orchestrating data flows, Best travel cameras
, the Informatica Complete Reference offers valuable insights and guidance.
Thank you for sharing this. visit: Python Online Training
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteI believe there are many more pleasurable opportunities ahead for individuals that looked at your site.
ReplyDeleteniğde
ReplyDeletekırklareli
osmaniye
siirt
urfa
BEG76S
https://saglamproxy.com
ReplyDeletemetin2 proxy
proxy satın al
knight online proxy
mobil proxy satın al
3D84PT
Great post.
ReplyDeleteFull-stack course in Nagpur
Recently I saw your blog, thanks for the information. Internet Marketing
ReplyDeleteNice article keep posting.
ReplyDeletepython full stack developer
Get the Career Growth with Advanced Skills at Surat’s No. 1 advanced IT Training Institute with 100% Job guarantee
ReplyDeletehttps://www.iforward.in/
Brown t경기도he hamburger meat and add the chili seasoning, garlic salt and cumin and simmer for 15 minutes
ReplyDeleteAweome Post. Thanks to share the Valuable Information. Now If You want to know about Who is View메인ing your Instagram account then visit here to know about
ReplyDeleteI like reading an article that will make people think. Also, thank you for permitting me to c함평출장샵omment!
ReplyDeleteThanks a lot for providing an interesting information. The Science of Patterns: Exploring Data Science in Practice
ReplyDeletespoken english classes, spoken english malayalam, oet writing, oet grammar, writing tips oet, trending oet, oet classes malayalam, oet online course for nurses free, oet online training
ReplyDeleteUseful post Thanks for sharing it ,that truly valuable knowledge about similar topic. checkout my blog Tableau training in pune it will help to gain knowledge about the importance of tableau software in IT industries. thank you
ReplyDeleteThe Combination Administration questions the query source in light of the query ports in the change and a query condition. The Query change returns the aftereffect of the query to the objective or another change. You can design the Query change to return a solitary line or numerous columns.
ReplyDeletetraffic lawyer botetourt va
This comment has been removed by the author.
ReplyDeleteحصان البوني
ReplyDeleteGet a connected worth. Recover a worth from the query table in light of a worth in the source. For instance, the source EMP table having DEPTNO however we don't have DNAME. We can get it by doing query on DEPT table in view of condition DEPT.DEPTNO=EMP.DEPTNO.
ReplyDeleteIn today's data-driven world, the ability to visualize and interpret data is crucial for making informed business decisions. APTRON Gurgaon offers comprehensive Tableau Training in Gurgaon that equips you with the skills to turn complex data into clear, actionable insights. Whether you're a beginner or an experienced professional, our courses are tailored to meet your needs.
ReplyDeletefgdsfgdfhbfdh
ReplyDeleteشركة عزل اسطح
dfvdxfgdfhgfdjh
ReplyDeleteشركة عزل اسطح
<a href="https://fenunalmthaleya.com/%d8%b4%d8%b1%d9%83
ReplyDeleteThanks for the info, Much Appreciated!! Office Interior Designer
ReplyDeleteAppreciate the valuable insights—thank you!
ReplyDeletebuy sony dsc qx10,
Thank you for sharing this valuable guide on DSC Apply Online. I spent all the days visiting a lot of websites, but I've never had a simple and clearly explain like here. Screenshots may help for new users even more [maybe add them in the future if possible] and maybe a video tutorial [if it is possible to have that as well]? Great work!
ReplyDeleteThanks for sharing your info. I truly appreciate your efforts and I am waiting for your next post thank you once again.
ReplyDeleteNodeJS Online Course from Malaysia
EC Council Certified SOC Analyst Certification Online Training from Hyderabad
Certified SCRUMMaster CSM Online Training from India
Oracle Supply Chain Management Training from Hyderabad
Best SAP Customer Activity Repository Training from Hyderabad
Thanks for sharing such an amazing content
ReplyDeleteDevops Training in Ameerpet
Thank you for sharing this informative resource. It offers useful guidance for anyone searching for a trusted full stack training institute in Mylapore. This information is beneficial for both students and working professionals aiming to enhance their technical skills and build strong career opportunities in the IT industry.
ReplyDelete